
Reinicios aleatorios en equipos VSP 4450
Problema
Se tienen varios equipos VSP 4450 en la release 8.1.x de VOSS. Se observan reinicios aleatorios (2 en un intervalo de 3 meses). Sin ninguna relación aparente con el funcionamiento de la red en el momento del reinicio.
Investigación
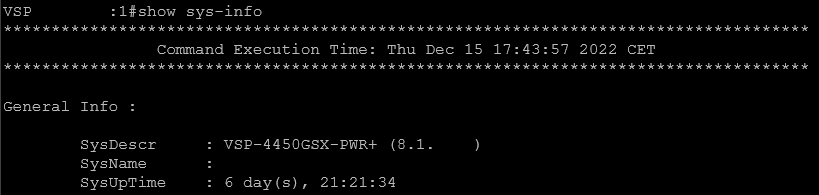
Lo primero que se observa en el equipo afectado, con el comando show sys-info es que se reinició, como indica el valor de SysUpTime.
A continuación, busco eventos en el log en el día que se reinició con el comando show logging file tail | include "boot" que muestra lo siguiente:

El sistema completó un reinició aproximadamente a las 20:25. Veo además los siguientes log, que son indicación clave de la causa del problema:
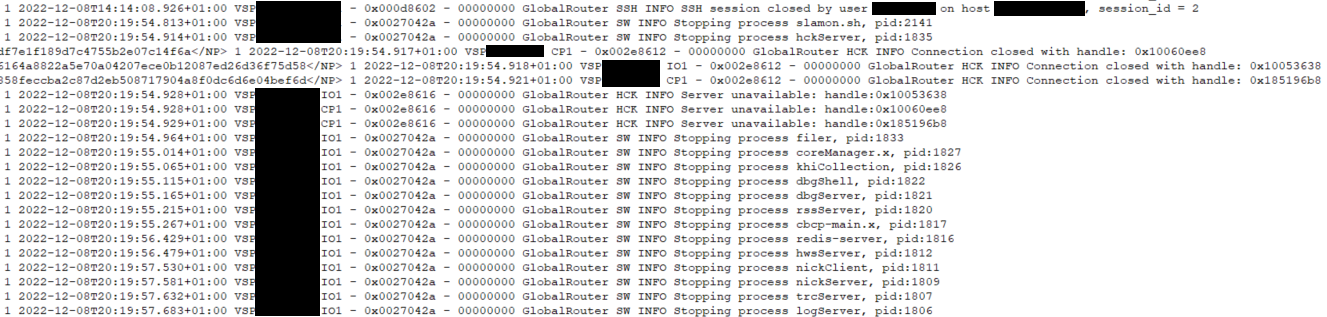
Como se observa, el sistema estaba funcionando correctamente hasta las 20:19, cuando aparecen los siguientes log:
00000000 GlobalRouter SW INFO Stopping process slamon.sh, pid:2141
00000000 GlobalRouter SW INFO Stopping process hckServer, pid:1835
00000000 GlobalRouter HCK INFO Connection closed with handle: 0x10060ee8
00000000 GlobalRouter HCK INFO Connection closed with handle: 0x10053638
00000000 GlobalRouter HCK INFO Connection closed with handle: 0x185196b8Seguido de varios mensajes similares, lo cual indica que se trata probablemente de un bug.
Buscando información sobre estos mensajes ("GlobalRouter SW INFO Stopping process slamon.sh"), llego a un artículo de Extreme (Switch Rebooted With Core Following "ERROR: Assertion failed ....sync.c:655") que muestra un problema similar e indicando como suponía antes que se trata de un defecto de software.
Otra páginas del soporte de Extreme Networks que analizan este problema:
VSP 4450 crashed with core file
Donde se dice que el problema lo causa un defecto de software con código interno VOSS-27032 y que afecta a toda la release 8.1.x.
Para investigar más allá, se pueden sacar los core files del equipo, que vienen a ser unos reportes/logs de ayuda para el equipo de soporte de Extreme en caso de abrir un caso de soporte.
Estos ficheros se generan automáticamente cuando el equipo crashea, para encontrar su ubicación se usa el comando show core-files:

Se observa en la anterior captura que hay 3 core files, correspondientes a 3 crashes del equipo respectivamente. Cuadra la fecha del segundo core file en este caso con los logs de antes (2022-12-08 a las 20:21).
Conectado por FTP al equipo voy a la ruta indicada y saco el fichero TAR. Este fichero descomprimido contiene estos archivos:
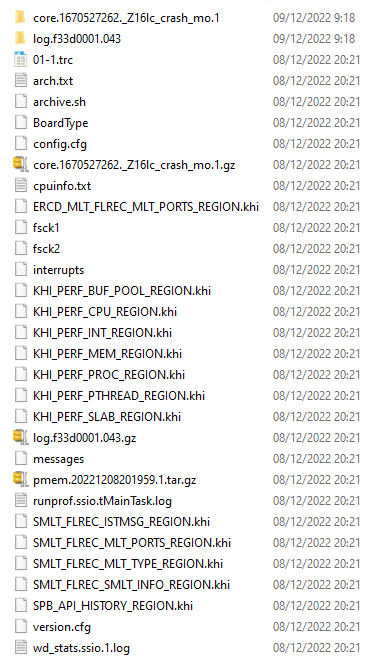
Los ficheros de interes en este caso serían:
- log.f33d0001.043.gz -- comprimido que contiene un fichero con mensajes de log
- messages -- fichero de importancia que contiene los logs sobre el crash
En el fichero "messages" se observa:
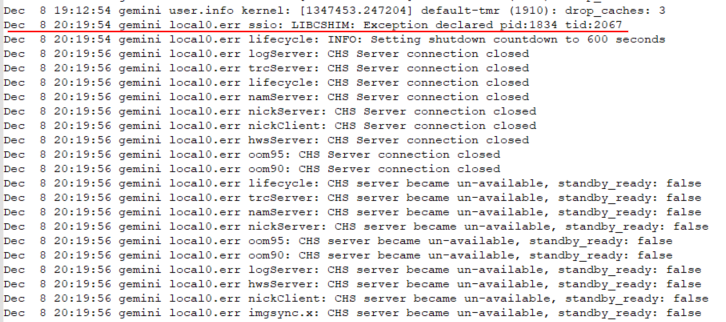
Se indica que todo se origina por una excepción en el software:
Dec 8 20:19:54 gemini local0.err ssio: LIBCSHIM: Exception declared pid:1834 tid:2067No sé que función realiza exactamente LIBCSHIM pero lo que está claro es que concuerda con el artículo de Extreme donde se dice:
Issue due to software bug VOSS-27032 which is tracked to an older SDK version used with VOSS 8.1 release
Solución
Actualizar el equipo a la versión más reciente disponible de VOSS o, como indican en el artículo de soporte:
Upgrade to 8.7.0.1 or later